Showing posts with label THEORY. Show all posts
Showing posts with label THEORY. Show all posts
Tuesday, July 3, 2012
Explain Plan Definitation
Operation Option Description
AND-EQUAL Thes step will have two or more child steps each of which returns a set of ROWID's.The AND-EQUAL operation selects onlyl those ROWIDs that returned by all the child operations.
BITMAP CONVERSION TO ROWIDS Converts a bitmap from a bitmap index to a set of ROWIDs that can be used to retrieve the actual data.
BITMAP CONVERSION FROM ROWIDS Converts a set of ROWIDs into a bitmapped representation.
BITMAP CONVERSION COUNT Counts the number of rows represented by a bitmap.
BITMAP INDEX SINGLE VALUE Looks up the bitmap for a single key value in the index.
BITMAP RANGE SCAN Retrieves bitmaps for a key value range.
BITMAP FULL SCAN Performs a full scan of a bitmap index if there is no start or stop key.
BITMAP MERGE Merges several bitmaps resulting from a range scan into one bitmap.
BITMAP MINUS Subtracts bits of one bitmap from another. Row source is used for negated predicates. Can be used only if there are nonnegated predicates yielding a bitmap from which the subtraction can take place. An example appears in "Viewing Bitmap Indexes with EXPLAIN PLAN".
BITMAP OR Computes the bitwise OR of two bitmaps.
BITMAP AND Computes the bitwise AND of two bitmaps.
BITMAP KEY ITERATION Takes each row from a table row source and finds the corresponding bitmap from a bitmap index. This set of bitmaps are then merged into one bitmap in a following BITMAP MERGE operation.
CONNECT BY Retrieves rows in hierarchical order for a query containing a CONNECT BY clause.
CONCATENATION Operation accepting multiple sets of rows returning the union-all of the sets.
COUNT Operation counting the number of rows selected from a table.
COUNT STOPKEY Count operation where the number of rows returned is limited by the ROWNUM expression in the WHERE clause.
DOMAIN INDEX Retrieval of one or more rowids from a domain index. The options column contain information supplied by a user-defined domain index cost function, if any.
FILTER Operation accepting a set of rows, eliminates some of them, and returns the rest.
FIRST ROW Retrieval of only the first row selected by a query.
FOR UPDATE Operation retrieving and locking the rows selected by a query containing a FOR UPDATE clause.
HASH JOIN Operation joining two sets of rows and returning the result. This join method is useful for joining large data sets of data (DSS, Batch). The join condition is an efficient way of accessing the second table.
(These are join operations.) CBO uses the smaller of the two tables/data sources to build a hash table on the join key in memory. Then it scans the larger table, probing the hash table to find the joined rows.
HASH JOIN ANTI Hash anti-join.
HASH JOIN SEMI Hash semi-join.
INDEX UNIQUE SCAN Retrieval of a single rowid from an index.
(These are access methods.)
INDEX RANGE SCAN Retrieval of one or more rowids from an index. Indexed values are scanned in ascending order.
INDEX RANGE SCAN DESCENDING Retrieval of one or more rowids from an index. Indexed values are scanned in descending order.
INDEX FULL SCAN Retrieval of all rowids from an index when there is no start or stop key. Indexed values are scanned in ascending order.
INDEX FULL SCAN DESCENDING Retrieval of all rowids from an index when there is no start or stop key. Indexed values are scanned in descending order.
INDEX FAST FULL SCAN Retrieval of all rowids (and column values) using multiblock reads. No sorting order can be defined. Compares to a full table scan on only the indexed columns. Only available with the cost based optimizer.
INDEX SKIP SCAN Retrieval of rowids from a concatenated index without using the leading column(s) in the index. Introduced in Oracle9i. Only available with the cost based optimizer.
INLIST ITERATOR Iterates over the next operation in the plan for each value in the IN-list predicate.
INTERSECTION Operation accepting two sets of rows and returning the intersection of the sets, eliminating duplicates.
MERGE JOIN Operation accepting two sets of rows, each sorted by a specific value, combining each row from one set with the matching rows from the other, and returning the result.
(These are join operations.)
MERGE JOIN OUTER Merge join operation to perform an outer join statement.
MERGE JOIN ANIT Merge anti-join.
MERGE JOIN SEMI Merge semi-join.
MERGE JOIN CARTESIAN Can result from 1 or more of the tables not having any join conditions to any other tables in the statement. Can occur even with a join and it may not be flagged as CARTESIAN in the plan.
MINUS Operation accepting two sets of rows and returning rows appearing in the first set but not in the second, eliminating duplicates.
NESTED LOOPS Operation accepting two sets of rows, an outer set and an inner set. Oracle compares each row of the outer set with each row of the inner set, returning rows that satisfy a condition. This join method is useful for joining small subsets of data (OLTP). The join condition is an efficient way of accessing the second table.
(These are join operations.)
NESTED LOOPS OUTER Nested loops operation to perform an outer join statement.
PARTITION SINGLE Access one partition.
PARTITION ITERATOR Access many partitions (a subset).
PARTITION ALL Access all partitions.
PARTITION INLIST Similar to iterator, but based on an IN-list predicate.
PARTITION INVALID Indicates that the partition set to be accessed is empty.
Iterates over the next operation in the plan for each partition in the range given by the PARTITION_START and PARTITION_STOP columns. PARTITION describes partition boundaries applicable to a single partitioned object (table or index) or to a set of equi-partitioned objects (a partitioned table and its local indexes). The partition boundaries are provided by the values of PARTITION_START and PARTITION_STOP of the PARTITION.
REMOTE Retrieval of data from a remote database.
SEQUENCE Operation involving accessing values of a sequence.
SORT AGGREGATE Retrieval of a single row that is the result of applying a group function to a group of selected rows.
SORT UNIQUE Operation sorting a set of rows to eliminate duplicates.
SORT GROUP BY Operation sorting a set of rows into groups for a query with a GROUP BY clause.
SORT JOIN Operation sorting a set of rows before a merge-join.
SORT ORDER BY Operation sorting a set of rows for a query with an ORDER BY clause.
TABLE ACCESS FULL Retrieval of all rows from a table.
(These are access methods.)
TABLE ACCESS SAMPLE Retrieval of sampled rows from a table.
TABLE ACCESS CLUSTER Retrieval of rows from a table based on a value of an indexed cluster key.
TABLE ACCESS HASH Retrieval of rows from table based on hash cluster key value.
TABLE ACCESS BY ROWID RANGE Retrieval of rows from a table based on a rowid range.
TABLE ACCESS SAMPLE BY ROWID RANGE Retrieval of sampled rows from a table based on a rowid range.
TABLE ACCESS BY USER ROWID If the table rows are located using user-supplied rowids.
TABLE ACCESS BY INDEX ROWID If the table is nonpartitioned and rows are located using index(es).
TABLE ACCESS BY GLOBAL INDEX ROWID If the table is partitioned and rows are located using only global indexes.
TABLE ACCESS BY LOCAL INDEX ROWID If the table is partitioned and rows are located using one or more local indexes and possibly some global indexes.
Partition Boundaries -- The partition boundaries might have been computed by:
A previous PARTITION step, in which case the PARTITION_START and PARTITION_STOP column values replicate the values present in the PARTITION step, and the PARTITION_ID contains the ID of the PARTITION step. Possible values for PARTITION_START and PARTITION_STOP are NUMBER(n), KEY, INVALID.
The TABLE ACCESS or INDEX step itself, in which case the PARTITION_ID contains the ID of the step. Possible values for PARTITION_START and PARTITION_STOP are NUMBER(n), KEY, ROW REMOVE_LOCATION (TABLE ACCESS only), and INVALID.
UNION Operation accepting two sets of rows and returns the union of the sets, eliminating duplicates.
VIEW Operation performing a view's query and then returning the resulting rows to another operation.
OTHER_TAG Column Text
Tag Text Meaning Interpretation
blank Serial execution.
SERIAL_FROM_REMOTE (S->R) Serial from remote Serial execution at a remote site.
SERIAL_TO_PARALLEL (S->P) Serial to parallel Serial execution; output of step is partitioned or broadcast to parallel execution servers.
PARALLEL_TO_PARALLEL (P->P) Parallel to parallel Parallel execution; output of step is repartitioned to second set of parallel execution servers.
PARALLEL_TO_SERIAL (P->S) Parallel to serial Parallel execution; output of step is returned to serial "query coordinator" process.
PARALLEL_COMBINED_WITH_PARENT (PWP) Parallel combined with parent Parallel execution; output of step goes to next step in same parallel process. No interprocess communication to parent.
PARALLEL_COMBINED_WITH_CHILD (PWC) Parallel combined with child Parallel execution; input of step comes from prior step in same parallel process. No interprocess communication from child.
Friday, April 27, 2012
Analyze Process and Lock
Analyze table estimate or compute statistics will acquire an exclusive lock on the library cache object, preventing any ddl changes, however dml on the table should be able to proceed. Analyze table validate structure, however, acquires an exclusive lock on the table, preventing any inserts/updates/deletes. In general, ANALYZE ... VALIDATE STRUCTURE requires an exclusive lock on the object being analyzed. Other permutations of ANALYZE should allow concurrent DML access.An exclusive lock doesn't prevent other people from reading the data, users should still be able to select from the table.
Issuing an analyze on an index puts a shared lock on the table. This means that you cannot do DML on the table that is locked. The DML
operation will wait for the analyze to release the lock. This lock can be viewed in v$lock. The lock Type will be TM and the Object id of the table is v$lock.id1. If there are transactions already against the table, then trying to do an analyze will give ora-54 resource busy.
select * from v$lock where type='TM';
Tuesday, April 17, 2012
Difference Oracle on Windows & Unix
Advantages of Oracle UNIX:
Significant performance improvement
Provides High Availability
Contains in-depth system utilities and open-source code
Highly respected by Oracle personnel
Advantages of Oracle Windows:
Very easy to deploy and support
Requires far less IT training
Simple interface to Microsoft tools such as ODBC and .NET.
In my personal opinion, here are some specific disadvantages to Linux and Windows:
Disadvantages of Oracle UNIX:
Required specialized skills (vi editor, shell scripting, etc.)
Required highly-technical Systems Administrators and DBA
Contains in-depth system utilities and open-source code
Security Holes (if mis-configured)
Susceptible to root kit attacks
Disadvantages of Oracle Windows:
Slower than Linux
Less glamorous for the SA and DBA
History of poor reliability (bad reputation)
Security Holes (if mis-configured)
Susceptible to Internet viruses
The main disadvantage is regarding the requirements for a technical staff that is proficient in shell scripting, the vi editor and the cryptic UNIX command syntax.
Unlike the easy-to-use Windows GUI, Linux and proprietary UNIX often require cryptic shell scripts to perform basic Oracle functions. Given the vast differences in administration, begin with looking at porting from UNIX to Windows.
The core difference is that in UNIX the OS controls the operations, while in Windows the Oracle database controls the operations.
There is also the issue of the expense of licensing the proprietary UNIX software such as Solaris, AIX, and HP UNIX, which can be tens of thousands of dollars. This has led many companies to consider the public-domain Linux option. To understand the benefits and shortcomings of Linux, you must take a closer look at Linux technology.
With the increasing popularity of Intel-based database servers, Oracle shops are struggling to make the choice between Linux and Windows for their Oracle databases. As we may know, Windows has suffered from a history of unreliability and Linux suffers because of it’s nascent technology and lack of support.
Find here major differences of Oracle on Unix, Linux and Windows.
Windows is multitasking but doesn't multi user operating system. Unix/Linux is multitasking, multiuser and Multithreading operating system.
For installation of Oracle on windows doesn't require any other user creation, we can perform oracle installation using "administrator" superuser of windows. For installation of Oracle on Unix/linux required to creating separate operating system user account. Using super user "root" we doesn't require to perform Oracle installation.
For installation of Oracle on windows, if we create separate operating system then it should be group of super user administrator. For installation of Oracle on Unix/Linux, when we create operating system user then it should be not part of super user group.
Default location of password file and parameter file for Windows is ORACLE_HOME\database folder.Default location of password file and parameter file for Unix/Linux is ORACLE_HOME/dbs folder.
ORACLE_BASE,ORACLE_HOME,ORACLE_SID are defined in registry of Windows as HKEY_LOCAL_MACHINE\SOFTWARE\ORACLE\HOME0. ORACLE_BASE,ORACLE_HOME,ORACLE_SID are defined as user's environment variables in Unix/Linux.
Symbolic links are NOT supported for user's environment variables or registry parameter in Windows. Symbolic links are supported for user's environment variables in Unix/Linux.
In windows we should need to set environment variable using "set" command and it doesn't save in user profile. In Unix and Linux we should need to set environment variable using "export" command and it can save using .profile (in Unix) and .bash_profile (in Linux).
Oracle's shared libraries are called as shared DLL in windows. Oracle's shared libraries are available in Unix/Linux.
Relinking of Oracle executable is not available in Windows. Relinking of Oracle executable is available in Unix/Linux.
Shared memory , shared segments and semaphores are NOT adjustable in Windows. Shared memory segment(SHMMAX), shared segments (SHMMNI) and semaphores (SEMMNS) are adjustable using kernel parameters in Unix/Linux.
Oracle's SGA locking in real memory doesn't possible in Windows. Oracle's SGA locking in real memory is possible in Unix/Linux.
Each background process of Oracle is implementing as Thread inside single process in Windows. Each background process of Oracle is a process in Unix/Linux.
Windows called as GUI because it provides Graphical User Interface. Unix and Linux called as CLUI called Command Line User Interface. Due to this reason Unix and Linux provides more performance than Windows due to resource utilization.
Oracle on Unix,Linux & Windows: Comparison of Oracle on operating system level with memory,disk I/O, security, Installation etc . View large
Windows is flat file system. Unix and Linux is hierarchical model file system. Windows kernel stores in couple of files like Registry. Unix and Linux kernel stores in many files which are hierarchy. It is very easy to understand Unix and Linux file systems in any version.
Earlier FAT and FAT32 file system has no security in Windows. Using NTFS file system windows use file permission based security. In Unix and Linux has traditional file permission security with owner,group and other users.Unix has greater built-in security and permissions features than Windows. Linux contains also same type of security and permissions logic like Unix.
There are very few utilities available in Windows for performance monitoring and administration. There are lot of command line utilities are available in Unix/Linux for performance monitoring and administration.
Source code of Operating system doesn't available in Windows. Source code of Operating system is available in some of Linux flavors, means we can modify source code of operating system.
Oracle on Windows magnetize because easy to understand, easy to maintain, easy to develop, resource availability and with good support. Oracle on Unix/Linux is not easy to understand,easy to maintain or easy to develop because it requires high skill set and depth knowledge.
Oracle deployment is very easy in Windows because not need to more knowledge or special skill sets. Oracle deployment is not easy in Unix/Linux because it requires special skill sets.
Windows is user friendly operating system. Unix and Linux doesn't user friendly operating system.
There is high risk of virus attacks on Windows. Because majority of windows users run as Administrator and virus can be affecting on any of files of kernel due to super user account. There is minimum risk for virus attacks on Unix and Linux. Because most of Unix box or Linux box is being run by user interface not using "root" super user. Due to this reason virus attacker cannot able to modify kernel of operating system.
Oracle on Windows magnetize because easy to understand, easy to maintain, easy to develop, resource availability and with good support.Oracle on Unix/Linux is not easy to understand,easy to install, maintain or easy to develop because it requires high skill set and depth knowledge.
Above reasons explain that, Oracle database administration on Unix and Linux requires extra knowledge and special expertise. Oracle on Linux and Unix provides best security and performance. Large and critical databases are running on Linux, Unix and Windows. Remote DBA Services provider has expertise to manage all type operating systems and all versions of Oracle.
Thursday, March 29, 2012
Oracle Parallel Execution
1. What is Oracle Parallel Execution?
Parallel Execution allows Oracle to perform specific database actions in parallel.
2. Which sub types of Parallel Execution exist?
The following types of Parallel Execution are most important:
Parallel Query
Parallel Query allows to parallelize certain components of selections, e.g.:
Full table scans
Index fast full scans
Access to inner tables of nested loop joins
Parallel DML
Parallel DML allows to parallelize DML operations:
UPDATE
DELETE
INSERT
Parallel DDL
Parallel DDL allows to parallelize DDL operations, e.g. :
CREATE INDEX
ALTER INDEX REBUILD
CREATE TABLE AS SELECT
Parallel Recovery
Parallel Recovery can be used to parallelize recovery activities:
RECOVER DATABASE
The most important Parallel Execution type is Parallel Query. Therefore this note focuses on the Parallel Query type. Nevertheless the technical details apply in the same way also to the other Parallel Execution types.
3. What are the advantages of Parallel Execution?
Based on Parallel Execution you are able to use more system resources like CPU or I/O at the same time for a specific operation. As a consequence the total runtime can significantly decrease.
4. What are restrictions and disadvantages of Parallel Execution?
The following disadvantages are possible:
Resource bottlenecks
Executing an operation in parallel involves increased resource usage (e.g. CPU or I/O). In the worst case a bottleneck situation can be the consequence and the whole system performance is impacted.
High parallelism in case of DEFAULT degree and many CPUs
If a Parallel Execution is performed with DEFAULT degree, a very high parallelism is possible. In order to avoid this it is usually recommended not to use the DEFAULT degree.
Wrong CBO decisions
Activated Parallel Query can significantly impact the calculations of the Cost Based Optimizer (see note 750631). In the worst case a good (sequential) index access can turn into a long running (parallel) full table
scan.
No RBO support
Parallel Query requires the CBO because the Rule Based Optimizer isn't able to handle it. If the CBO is used for an access on tables without statistics, this can cause performance problems.
Parallel DDL activates segment parallelism
If a parallel DDL operation like ALTER INDEX REBUILD PARALLEL is performed, the parallelism degree for the index remains even after the DDL operation is finished. As a consequence unintentionally parallel query
might be used. In order to avoid problems you have to make sure that you reset the parallelism degree of the concerned segments to 1 after the DDL operation. The BR*TOOLS perform this activity automatically after
parallelized DDL operations.
Wrong result sets with 10g
Due to the Oracle bug described in note 985118 it is possible that Parallel Executions return a wrong result set.
Insufficient explain information
With older SAP releases parallel query is not taken into account in the explain functionality in transaction ST04 or ST05 (see note 723879). As a consequence misconceptions and irritations are possible.
Shared pool allocation
Parallel query can consume significant amounts of shared pool memory for communication purposes. Particularly in the case of high values for PARALLEL_MAX_SERVERS and
PARALLEL_EXECUTION_MESSAGE_SIZE up to several GB of shared pool memory can be allocated. A consequence can be ORA-04031 errors (see note 869006).
No parallel DML with IOTs
It is not possible to use parallel DML in combination with (unpartitioned) Index Organized Tables (IOTs).
5. How is Parallel Execution performed on a technical layer?
The following processes are used to perform a Parallel Execution:
Parallel Execution Coordinator
The Parallel Execution Coordinator (later on referred to as "coordinator") is the control process that distributes the work across the Parallel Execution Slaves.
Up to Oracle 9i the coordinator splits SQL statements into smaller pieces (in terms of the working set) and passes the "smaller" SQL commands to the Parallel Execution Slaves. Typical SQL statements that
are transformed by the coordinator look like:
SELECT /*+ CIV_GB */ A1.C0,AVG(SYS_OP_CSR(A1.C1,0)), MAX(SYS_OP_CSR(A1.C1,1)) FROM :Q490001 A1 GROUP BY A1.C0
SELECT /*+ PIV_GB */ A1.C1 C0,SYS_OP_MSR(AVG(A1.C0),MAX(A1.C0)) C1 ...
... /*+ ORDERED NO_EXPAND USE_HASH(A3) */ ...
... /*+ Q354359000 NO_EXPAND ROWID(A4) */ ...
... PX_GRANULE(0, BLOCK_RANGE, DYNAMIC) ...
SELECT /*+ PIV_SSF */ SYS_OP_MSR(MAX(A1.C0)) FROM ...
As of 10g the original SQL statement is passed to the Parallel Execution Slave without any transformation.
Parallel Execution Slaves (in the following named "slaves")
There are two types of Parallel Execution Slaves:
Producers
The producers read the source data and pass it to the consumers or the coordinators.
Consumers
The consumers take the data from the producers and process it. Consumers are only needed if the data from the producers needs to be post-processed (e.g. sorted).
The communication and data transfer between the processes is based on queues. The communication structures are part of the shared pool:
PX msg pool
Communication area for the parallel query processes
Size depends mainly on PARALLEL_EXECUTION_MESSAGE_SIZE, PARALLEL_MAX_SERVERS and the actually used parallel query slaves
PX subheap
Memory structure with additional parallel query related information
Usually small compared to "PX msg pool"
Blocks that are read via Parallel Execution are always read directly from disk bypassing the Oracle buffer pool. For more information about this "direct path" operation see the "direct path read" section in note
619188.
In order to make sure that the most recent data is read from disk a segment specific checkpoint is performed before the "direct path read" operations are started.
6. Which parameters exist in relation to Parallel Execution?
The following Oracle parameters are most important with regards to Parallel Execution:
CPU_COUNT
CPU_COUNT is a parameter that reflects the number of CPUs on the database server. It is used for several Oracle internal purposes and also influences the DEFAULT parallelism used by Oracle (see below).
As CPU_COUNT influences Oracle at a lot of locations, the default value should not be changed.
PARALLEL_EXECUTION_MESSAGE_SIZE
This parameter determines the size of the communication buffer between the differen Parallel Execution processes.
In order to avoid a bottleneck it's recommended to set this parameter to 16384.
PARALLEL_INSTANCE_GROUP
This parameter can be used in RAC environments in order to restrict Parallel Executions to a sub set of the existing RAC instances.
PARALLEL_MAX_SERVERS
With this parameter the maximum number of simultaneously active slave processes can be specified. If more slaves are requested at a certain time the requests are downgraded and a smaller parallelism is
used.
SAP recommends setting this parameter to 10 times the number of CPUs available for the Oracle database in OLAP and Oracle 10g environments.
PARALLEL_MIN_SERVERS
This parameter specifies how many slave processes are created during database startup. If more slaves are needed, they are created on demand.
It's recommended to keep this parameter on the default of 0 in order to avoid unnecessarily started slave processes.
PARALLEL_THREADS_PER_CPU
This parameter influences the DEFAULT parallelism degree (see below).
In order to avoid overload situations with DEFAULT parallelism it's recommended to set this parameter to 1.
PARALLEL_ADAPTIVE_MULTI_USER
When this parameter is set to TRUE (what is default for Oracle 10g) parallel executions may be downgraded by Oracle even before PARALLEL_MAX_SERVERS is reached in order to limit the system load. If
you need to guarantee maximum parallelization (like during reorganizations or system copies) it is advisable to set this parameter to FALSE. During normal operation the value TRUE should be okay because resource
bottlenecks can be avoided.
7. How are activation and degree of parallelism determined?
The following points have to be taken into account in order to determine if and to what extent Parallel Query is used:
The operation must be parallelizable (e.g. full table scan, scan of partitioned index). An index range scan on a non-partitioned index e.g. can't be performed in parallel.
The parallelism must be activated on segment or on statement level.
Segment level
Parallelism on segment level can be activated with the following command:
ALTER TABLE PARALLEL ;
ALTER INDEX PARALLEL ;
In order to check the parallelism for a certain segment, you can use the following selection:
SELECT DEGREE FROM DBA_TABLES WHERE TABLE_NAME = '';
SELECT DEGREE FROM DBA_INDEXES WHERE INDEX_NAME = '';
Statement level
On SQL statement level the following hint can be used to activate parallelism (see note 772497):
PARALLEL(, )
If is a positive number, up to producers and consumers can be used for a parallel query (-> 2 * slaves).
If DEFAULT is specified for , CPU_COUNT * PARALLEL_THREADS_PER_CPU producers and CPU_COUNT * PARALLEL_THREADS_PER_CPU consumers can be used for a parallel query.
If the PARALLEL_MAX_SERVERS limit is exceeded taking into account all simultaneously active Parallel Executions, the degree of parallelism is reduced.
8. To what extent does SAP use parallelism on segment and statement level?
Per default no segments with activated parallelism are delivered by SAP.
Parallelism on statement level (-> PARALLEL hint) is frequently used in BW environments (e.g. in case of aggregate rollup). In OLTP environments the PARALLEL hint is used only in exceptional situations.
9. How can segments with activated parallelism be determined?
With the following selection all tables and indexes can be determined that have a parallelism degree > 1 or DEFAULT:
SELECT
TABLE_NAME SEGMENT_NAME,
DEGREE,
INSTANCES
FROM DBA_TABLES
WHERE
OWNER LIKE 'SAP%' AND
(DEGREE != ' 1' OR INSTANCES != ' 1')
UNION
SELECT
INDEX_NAME SEGMENT_NAME,
SUBSTR(DEGREE, 1, 10) DEGREE,
SUBSTR(INSTANCES, 1, 10) INSTANCES
FROM DBA_INDEXES
WHERE
OWNER LIKE 'SAP%' AND
INDEX_TYPE != 'LOB' AND
(DEGREE != '1' OR INSTANCES NOT IN ('0', '1'));
10. How can the parallelism degree of segments be modified?
With the following commands the parallelism for a table or index can be deactivated:
ALTER TABLE PARALLEL (DEGREE 1 INSTANCES 1);
ALTER INDEX PARALLEL (DEGREE 1 INSTANCES 1);
In order to set the parallel degree to a certain value, you can use:
ALTER TABLE PARALLEL ;
ALTER INDEX PARALLEL ;
11. How can you determine to what extent the parallelism is downgraded?
The following selection returns how many Parallel Executions are downgraded to what extent:
SELECT NAME, VALUE FROM V$SYSSTAT
WHERE NAME LIKE 'Parallel operations%';
12. Which wait events exist with regards to Parallel Execution?
The following are the main wait events in the area of Parallel Execution (see note 619188 for more information on Oracle wait events). As it is difficult to distinguish between idle events and busy events in the area of
parallel execution, these two types are not distinguished.
PX Idle Wait
A slave waits for acquiration by a coordinator. This is a real idle event.
PX Deq: Execute Reply
The coordinator waits for slaves to finish their work.
PX Deq: Table Q Normal
A consumer waits for data from its producer.
PX Deq: Execution Msg
A slave waits for further instructions from the coordinator.
PX Deq Credit: send blkd
A producer wants to send something to its consumer, but the consumer has not finished the previous work, yet. The same is valid for a slave that want to send something to its coordinator.
In order to tune this wait event you have to check why the consumer / coordinator is not able to process the producer data fast enough. For example deactivated parallelism for DML operations can result in high "PX
Deq Credit: send blkd" waits for parallelized activities containing DML operations (e.g. INSERT ... SELECT). In this case "ALTER SESSION ENABLE PARALLEL DML" can optimize the parallelization.
If an SAP process fetches record by record from the database using parallel query and performs some processing on ABAP side in between, parallel execution slaves wait for "PX Deq Credit: send blkd" during the
ABAP processing. In this case huge wait times for this wait event and huge elapsed times for the SQL statement can be seen although the real execution time on database side is very small. In this scenario "PX Deq
Credit: send blkd" can be treated as an idle event.
PX qref latch
A consumer has to wait for its communication queue to be available. Make sure that PARALLEL_EXECUTION_MESSAGE_SIZE is set to 16384 in order to avoid many small communications and reduce this kind of
contention.
Another possible reason for "PX qref latch" waits is the fact that the consumer (or coordinator) processes the data slower than the producer generates it. In this case further optimization is hardly possible.
PX Deq: Signal ACK
PX Deq: Join ACK
PX Deq Credit: need buffer
These wait events are related to process communication: The coordinator waits for an acknowledgement of a control message ("PX Deq: Signal ACK") or join request ("PX Deq: Join ACK") from a slave or processes
need a queue buffer in order to send data ("PX Deq Credit: need buffer"). It is normal that these events occur (and so Oracle treats them partially as idle events), but if you have doubts that too much time is spent for
communicating, you should check for overall resource bottlenecks (e.g. CPU) and unnecessary parallelization of small tasks.
PX Deq: Parse Reply
The coordinator waits until the slaves have parsed their SQL statements. In case of increased waits for "PX Deq: Parse Reply" you should check if the shared pool is sized sufficiently (note 789011) and if there are
some parallel query SQL statements with a high parse time (note 712624 (24)).
reliable message
The coordinator waits for a reply from another instance in RAC environments. This can e.g. happen if Oracle parameters are set system wide using ALTER SYSTEM.
To a minor extent waits for "reliable message" can also show up in non RAC systems.
latch free (for "query server process" latch)
The "query server process" latch is allocated if an additional slaves are created. This is necessary if more slaves then defined with PARALLEL_MIN_SERVERS are needed. In order to optimize this kind of latch wait
you should check on the one hand side if Parallel Execution is activated by accident (e.g. on segment level) and switch it off in this case. Alternatively you can consider setting PARALLEL_MIN_SERVERS to a higher
value.
13. Where can I find more information about Parallel Execution activites on the system?
The following selection from V$PX_SESSION can be used to monitor the current activities of Parallel Execution processes:
SELECT
PS.SID,
DECODE(SERVER_SET, NULL, 'COORDINATOR', 1, ' CONSUMER',
' PRODUCER') ROLE,
DECODE(SW.WAIT_TIME, 0, SW.EVENT, 'CPU') ACTION,
SQ.SQL_TEXT
FROM
V$PX_SESSION PS,
V$SESSION_WAIT SW,
V$SQL SQ,
V$SESSION S,
AUDIT_ACTIONS AA
WHERE
PS.SID = SW.SID AND
S.SID = PS.SID AND
S.SQL_ADDRESS = SQ.ADDRESS (+) AND
AA.ACTION = S.COMMAND
ORDER BY PS.QCSID, NVL(PS.SERVER#, 0), PS.SERVER_SET;
In addition the following Parallel Execution related views exist:
V$PQ_SYSSTAT
The view V$PQ_SYSSTAT contains general information about Parallel Execution activities like number of Parallel Queries, Parallel DML and Parallel DDL or currently active sessions.
V$PQ_SLAVE
This view contains information about the existing parallel query slaves.
V$PQ_TQSTAT
Statistics for different parallel queries (separated by DFO_NUMBER)
14. How can the progress of a parallelized full table scan be monitored?
Create the following fuction in the schema of a user who has the the the privileges
grant analyze any to ;
grant select any table to ;
directly (not via role) granted. Usually not even the user 'SYS' has these privileges granted directly.
create or replace function sap_fts_progress_parallel
(owner varchar2, tab_name varchar2, sess number, blocks number)
RETURN char IS
stat_nr number;
tot_blk number;
unu_blk number;
dummy number;
query_act number;
perc number;
hwm number;
begin
if blocks=-1 then
dbms_space.unused_space(owner, tab_name, 'TABLE', tot_blk,
dummy, unu_blk, dummy, dummy, dummy, dummy, dummy);
hwm := tot_blk-unu_blk;
else
hwm := blocks;
end if;
select statistic# into stat_nr from v$statname
where name='physical reads direct';
select count(1) into query_act from v$px_sesstat
where statistic#=stat_nr
and qcsid=decode(sign(sess),1,sess,qcsid);
if query_act=0 then
return 'Query not active';
else
select sum(value)/decode(hwm,0,1,hwm)*100 into perc
from v$px_sesstat where statistic#=stat_nr
and sid <>qcsid
and qcsid=decode(sign(sess),1,sess,qcsid);
return to_char(perc,'999.9')||'% of '||to_char(hwm)||' Blocks';
end if;
end;
/
Doublecheck if the character '|' is copied when you cut and paste the function definition.
Execute the function with
select sap_fts_progress_parallel('','',,-1) from
is the object on which the query runs.
specifies the session id which initiated the query. For larger tables you can increase performance if you specify the total number of blocks given back from the first query at the second and all further executions:
',,)
dual;
when your parallel query is running to get the percentual progress and the total number of blocks to be read (example output: '43.7% of 6973 Blocks'). .
select sap_fts_progress_parallel('','
from dual;
If you are sure that there is no other parallel query running concurrently then you can also set equal '-1'. If - against the prerequisite - another query runs then the percentual value is undefined.
15. Which error can show up in relation to Parallel Execution?
The following errors are important in the area of Parallel Execution:
ORA-12801: error signaled in parallel query server
This error indicates that a parallel query process had to terminate due to an error situation. As described in note 636475, the ORA-12801 is a secondary Oracle error code. You have to check for the real error message
that accompanies the ORA-12801 error.
ORA-12805: parallel query server died unexpectedly
This error indicates that a parallel query process terminated in a hard way. In this case you have to analyze trace files and the alert log for more information.
16. How does the INSTANCES setting influence the parallelism?
The INSTANCES storage parameter is mainly intended for RAC environments and has a similar effect like the PARALLEL storage parameter. In order to avoid confusion it is recommended not to use the INSTANCES
parameter setting.
17. How can parallelism be activated on session level?
You can enable the different types of parallelism on session level using: ALTER SESSION ENABLE PARALLEL QUERY;
ALTER SESSION ENABLE PARALLEL DDL;
ALTER SESSION ENABLE PARALLEL DML;
While PARALLEL QUERY and PARALLEL DDL are activated per default, PARALLEL DML has to be activated explicitly if required. This can e.g. be useful in case of parallelized BRSPACE online reorganizations. Per
default only the reading of the source table is parallelized while the writing into the target table is done sequentially. By activating PARALLEL DML the writing can be parallelized.
Additionally it is also possible to force parallelism on session level even if no PARALLEL hint or segment parallelism is used:
ALTER SESSION FORCE PARALLEL QUERY PARALLEL ;
ALTER SESSION FORCE PARALLEL DDL PARALLEL ;
ALTER SESSION FORCE PARALLEL DML PARALLEL ;
Thursday, December 29, 2011
Database Hardening
Following are the general guidelines used for DB hardening:
Complete server hardening checklist. Ideally, run on latest supported version (or at least a supported version) of the Operating System.
Use the latest generation of database server.
Install the latest vendor-provided patches for the database. Be sure to include patches for database support software that isn’t directly bundled with the database.
Remove default usernames and passwords
Manually reviews installed stored procedures and delete those that aren’t going to be used. In many cases, most or all stored procedures can be deleted.
Where possible, isolate sensitive databases to their own servers. Databases containing Personally Identifiable Information, or otherwise sensitive data should be
protected from the Internet by a network firewall, and administrative/DBA access should be limited to as few individuals as possible.
Ensure that application access to the database is limited to the minimal access necessary. For example, reporting applications that just require read-only access should be appropriately limited.
Manually validate that logging of successful and failed authentication attempts is working.
Use complex names for database users. Use especially complex passwords for these users.
Create alternative administrative users for each DBA, rather than allowing multiple individual users to regularly use the default administrative account.
Wednesday, April 6, 2011
Constraint stats ORA-02298
Alter table CEXIST DISABLE constraint CEXISTBROKBOOK;
alter table CEXIST disable constraint CEXISTBOOK;
alter table CEXIST ENABLE constraint CK_COMPANYCATEGORY
alter table CEXIST ENABLE constraint CEXISTPRIMARY ;
alter table CEXIST ENABLE constraint COMPANYEXIST ;
SQL> alter table CEXIST ENABLE constraint CEXISTBOOK ;
alter table CEXIST ENABLE constraint CEXISTBOOK
*
ERROR at line 1:
ORA-02298: cannot validate (LDBO.CEXISTBOOK) - parent keys not found
alter table CEXIST MODIFY CONSTRAINTS CEXISTBOOK ENABLE VALIDATE;
ERROR at line 1:
ORA-02298: cannot validate (LDBO.CEXISTBOOK) - parent keys not found
alter table CEXIST MODIFY CONSTRAINTS CEXISTBOOK ENABLE NOVALIDATE;
Constraint stats
Here are the four type of constraint stats. These four constraint stats are applicable for all type of constraints(primary key, foreign key, check etc).
1. ENABLE VALIDATE
2. ENABLE NOVALIDATE
3. DISABLE VALIDATE
4. DISABLE NOVALIDATE
ENABLE VALIDATE is same as ENABLE. Constraint validate the data as soon as we entered in the table.
ENABLE NOVALIDATE is not same as ENABLE. Constraint validates the new data or modified data. It would not validate the existing data in table.
DISABLE NOVALIDATE is the same as DISABLE. The constraint is not checked so data may violate the constraint.
DISABLE VALIDATE means the constraint is not checked but disallows any modification of the constrained columns.
Note : Couple of things needs to be noted down here.
1. Converting NOVALIDATE constraint to VALIDATE would take longer time, depends on how big the data in the table. Although conversion in the other direction is not an issue
2. Disabling primary key constraint will drop the index associated with primary key. Again, when we enable the primary key constraint, it will create the index on the primary key column.
What is the ideal place to use ENABLE NOVALIDATE option?
In a busy environment, some one disabled the constraint accidently or intentionally, and we have already bad data in that table. Now business requested you to load the new set of data, but business wanted to make sure that new set of data should be validated during the load. At this circumstances, we can use ENABLE NOVALIDATE option. This option will validate the new data and old data will not be validated.
What is the ideal place to use DISABLE VALIDATE option?
We disabled the constraint for some reason. We do not want to load any data until we fix the issue and enable the constraint. We can use DISABLE VALIDATE option here. This option would not let you load any data when the constraint is disabled.
alter table CEXIST disable constraint CEXISTBOOK;
alter table CEXIST ENABLE constraint CK_COMPANYCATEGORY
alter table CEXIST ENABLE constraint CEXISTPRIMARY ;
alter table CEXIST ENABLE constraint COMPANYEXIST ;
SQL> alter table CEXIST ENABLE constraint CEXISTBOOK ;
alter table CEXIST ENABLE constraint CEXISTBOOK
*
ERROR at line 1:
ORA-02298: cannot validate (LDBO.CEXISTBOOK) - parent keys not found
alter table CEXIST MODIFY CONSTRAINTS CEXISTBOOK ENABLE VALIDATE;
ERROR at line 1:
ORA-02298: cannot validate (LDBO.CEXISTBOOK) - parent keys not found
alter table CEXIST MODIFY CONSTRAINTS CEXISTBOOK ENABLE NOVALIDATE;
Constraint stats
Here are the four type of constraint stats. These four constraint stats are applicable for all type of constraints(primary key, foreign key, check etc).
1. ENABLE VALIDATE
2. ENABLE NOVALIDATE
3. DISABLE VALIDATE
4. DISABLE NOVALIDATE
ENABLE VALIDATE is same as ENABLE. Constraint validate the data as soon as we entered in the table.
ENABLE NOVALIDATE is not same as ENABLE. Constraint validates the new data or modified data. It would not validate the existing data in table.
DISABLE NOVALIDATE is the same as DISABLE. The constraint is not checked so data may violate the constraint.
DISABLE VALIDATE means the constraint is not checked but disallows any modification of the constrained columns.
Note : Couple of things needs to be noted down here.
1. Converting NOVALIDATE constraint to VALIDATE would take longer time, depends on how big the data in the table. Although conversion in the other direction is not an issue
2. Disabling primary key constraint will drop the index associated with primary key. Again, when we enable the primary key constraint, it will create the index on the primary key column.
What is the ideal place to use ENABLE NOVALIDATE option?
In a busy environment, some one disabled the constraint accidently or intentionally, and we have already bad data in that table. Now business requested you to load the new set of data, but business wanted to make sure that new set of data should be validated during the load. At this circumstances, we can use ENABLE NOVALIDATE option. This option will validate the new data and old data will not be validated.
What is the ideal place to use DISABLE VALIDATE option?
We disabled the constraint for some reason. We do not want to load any data until we fix the issue and enable the constraint. We can use DISABLE VALIDATE option here. This option would not let you load any data when the constraint is disabled.
Monday, March 14, 2011
Oracle Database Incarnation, Open Resetlogs , SCN
Q. What happens when you run ALTER DATABASE OPEN RESETLOGS ?
The current online redo logs are archived, the log sequence number is reset to 1, new database incarnation is created, and the online redo logs are given a new time stamp and SCN.
.
Q. In what scenarios open resetlogs required ?
An ALTER DATABASE OPEN RESETLOGS statement is required after incomplete recovery (Point in Time Recovery) or recovery with a backup control file.
.
Q. What is SCN (System Change Number) ?
The system change number (SCN) is an ever-increasing value that uniquely identifies a committed version of the database at a point in time. Every time a user commits a transaction Oracle records a new SCN in redo logs.
Oracle uses SCNs in control files datafile headers and redo records. Every redo log file has both a log sequence number and low and high SCN. The low SCN records the lowest SCN recorded in the log file while the high SCN records the highest SCN in the log file.
.
Q. What is Database Incarnation ?
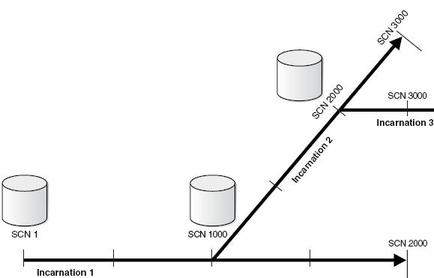
Database incarnation is effectively a new “version” of the database that happens when you reset the online redo logs using “alter database open resetlogs;”.
Database incarnation falls into following category Current, Parent, Ancestor and Sibling
i) Current Incarnation : The database incarnation in which the database is currently generating redo.
ii) Parent Incarnation : The database incarnation from which the current incarnation branched following an OPEN RESETLOGS operation.
iii) Ancestor Incarnation : The parent of the parent incarnation is an ancestor incarnation. Any parent of an ancestor incarnation is also an ancestor incarnation.
iv) Sibling Incarnation : Two incarnations that share a common ancestor are sibling incarnations if neither one is an ancestor of the other.
.
Q. How to view incarnation history of Database ?
Using SQL> select * from v$database_incarnation;
Using RMAN>LIST INCARNATION;
However, you can use the RESET DATABASE TO INCARNATION command to specify that SCNs are to be interpreted in the frame of reference of another incarnation.
•For example my current database INCARNATION is 3 and now I have used
FLASHBACK DATABASE TO SCN 3000;then SCN 3000 will be search in current incarnation which is 3. However if I want to get back to SCN 3000 of INCARNATION 2 then I have to use,
RMAN> RECOVER DATABASE TO SCN 3000;
Subscribe to:
Posts (Atom)